Machine Learning
Machine Learning (ML) software is a software system with one or more components that learn from data. This entails engineering a pipeline for the collection and pre-processing of data, the training of an ML model, the deployment of the trained model to perform inference and the software engineering of the encompassing software system that sends new input data to the model to get answers.
This post on ML projects explains why ML projects are different from traditional rule-based software engineering and identifies eight challenges for engineering machine learning applications:
- Data requirements engineering including data visualizations
- ML components are more difficult to handle as distinct modules
- Design of the ML component through algorithm selection and tuning
- Break up the ML development in increments
- Data and model management for the current and future projects
- Find ML models that can be reused for your application
- Validation of ML applications in absence of a specification to test against
- Explainability of ML models is needed for debugging
There is a research method called Data analytics (in the Lab strategy). This does not reflect the way of working in ML projects, where Data Analytics is not a method to answer one question but a method to fulfil the main goal of the project. For ML projects, the Data Analytics method should be divided in several smaller steps, each becoming a method of its own. In other words, we should treat the Data Analytics (or more appropriate ML engineering) process in the same way the software engineering process is treated in the DOT framework.
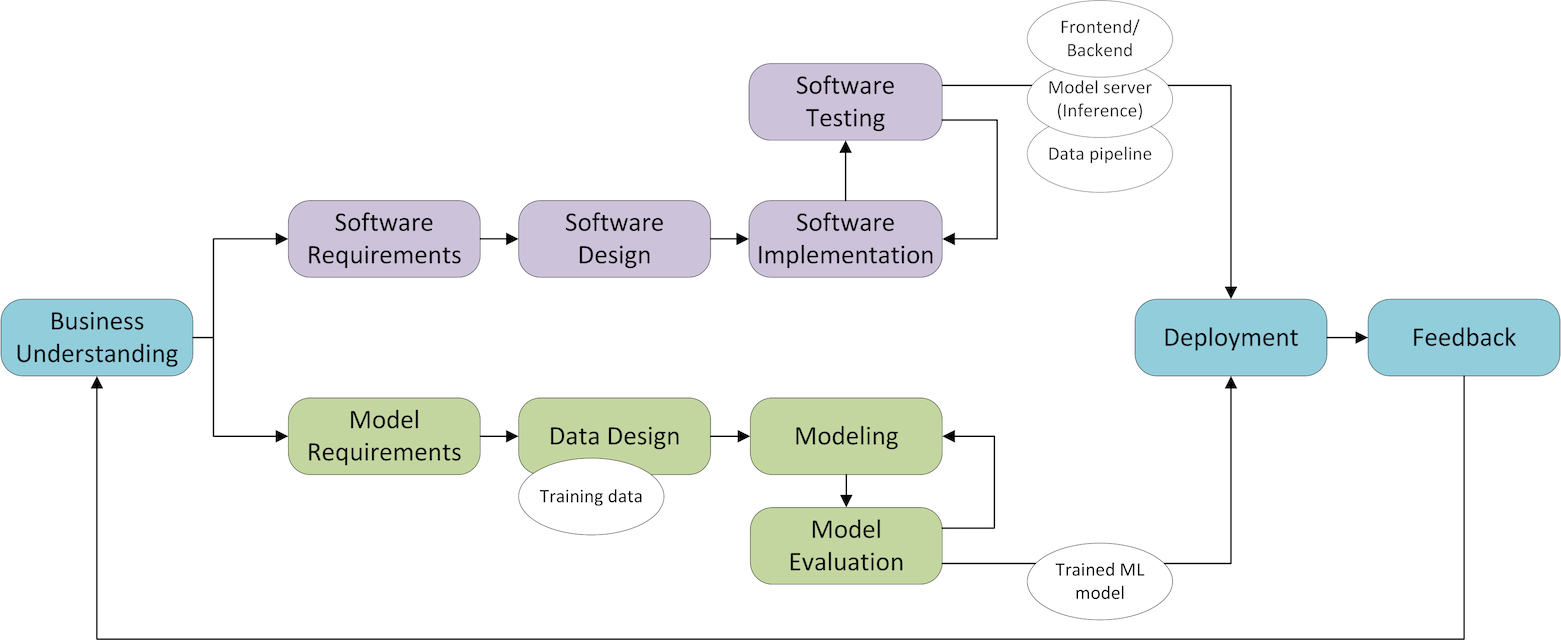
For that we can use the highly schematical picture from Figure 1. In green, it show us the steps (high-level, derived from CRISP-DM) that should be done in the machine learning part of the project. For the research methods this means the Data Analytics method should be replaced by several separate methods:
- Data collection. Based on the model requirements (what type of data?) and the business understanding (which content should be in the data?) we should collect the data that is needed to train the ML model.
- Exploratory data analysis (Field) . Instead of requirements we have input data. Instead of interviewing users to collect requirements we should explore the given data to learn what we can do with it. This is called Exploratory Data Analysis.
- Data preparation. Once we understand the data, we should transform the data so that it can be used for training an ML model.
- Data quality check (Lab). Next to testing the software we should also test the data. It is well known that with wrong input data, the model will also produce wrong answers.
- ML model training. The way to approach the training of ML models is very specific; algorithm selection and hyperparameter tuning are part of it.
- Model validation (Lab) . Next to testing software and data you also need to test the trained model.
- Model evaluation (Lab). Translate the ML model results to communicate and validate them with end users (e.g. through data visualization).
Data collection, data preparation and ML model training are engineering steps that do not qualify as ICT research methods. The other four methods require a “card” of their own for ML projects, but might also be useful in other types of projects.
For brief discussions of the other research methods and how they apply to ML projects, please refer to the next pages:
